Paweł Rościszewski, Jakub Kaliski
https://ieeexplore.ieee.org/iel7/8030510/8035032/08035128.pdf
In the paper we investigate the performance of parallel deep neural network training with parameter averaging for acoustic modeling in Kaldi, a popular automatic speech recognition toolkit.
We describe experiments based on training a recurrent neural network with 4 layers of 800 LSTM hidden states on a 100-hour corpora of annotated Polish speech data. We propose a MPI-based modification of the training program which minimizes the overheads of both distributing training jobs and loading and preprocessing training data by using message passing and CPU/GPU computation overlapping.
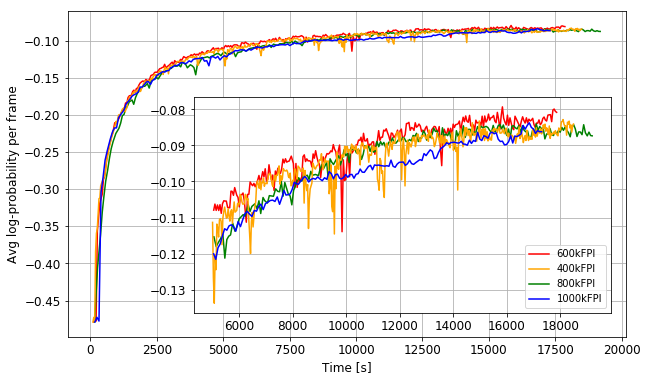
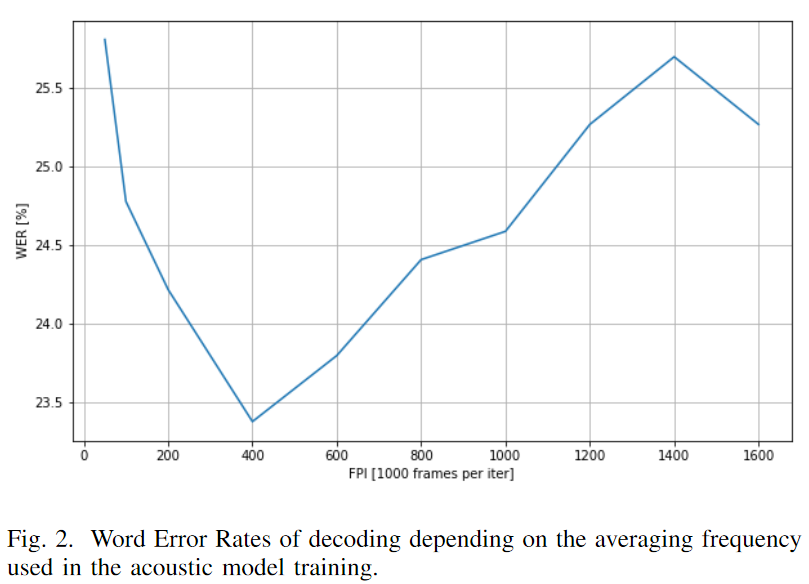
The impact of the proposed optimizations is greater for the more frequent neural network model averaging. To justify our efforts, we examine the influence of averaging frequency on the trained model efficiency. We plot learning curves based on the average log-probability per frame of correct paths for utterances in the validation set, as well as word error rates of test set decodings. Based on experiments with training on 2 workstations with 4 GPUs each we point that for the given network architecture, dataset and computing environment there is a certain range of averaging frequencies that are optimal for the model efficiency. For the selected averaging frequency of 600k frames per iteration the proposed optimizations reduce the training time by 54.9%.
2017 International Conference on High Performance Computing & Simulation (HPCS). IEEE, 2017. p. 560-565.